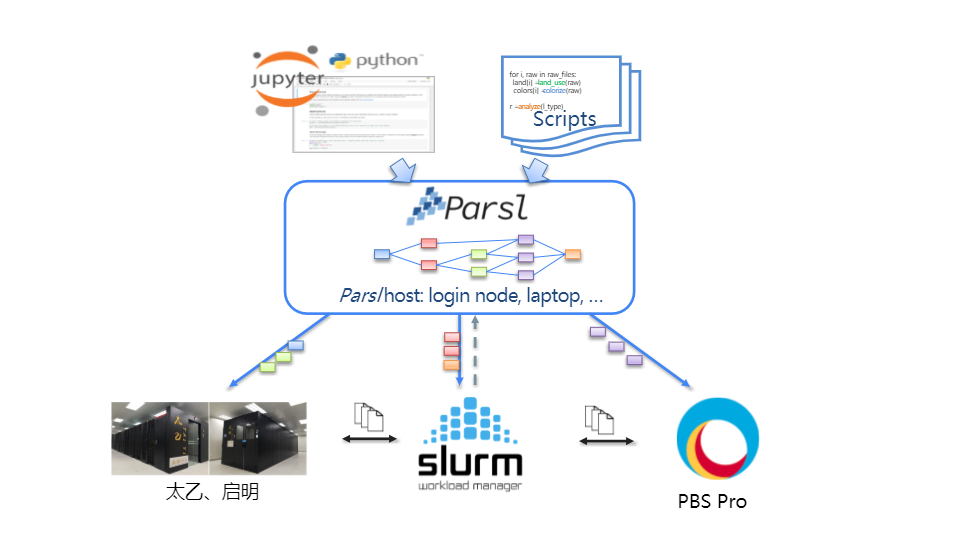
Parsl是一个基于Python的开源并行编程库,赋能用户在各类不同的集群上便捷地并行运行面向数据的大规模工作流。Parsl可以并行运行纯Python的工作流,亦可并行调用其它命令行工具或软件。Parsl完全基于Python,无需使用其它语言来构建工作流(例如YAML),易于安装,并能自动与超算的作业管理器进行交互,无需手动编写作业脚本。在Parsl中,工作流的构建和资源的管理完全分开,赋能用户便捷地在不同的计算集群上移植和运行相同的工作流,实现"Write once, run anywhere",如图1所示。Parsl已应用于多个科学领域的工作流中,在多个大型超算集群部署和验证,如美国国家能源研究科学计算中心(NESRC)等。
图1:Parsl可支持多种类型的超算集群,包括太乙、启明及基于Slurm和PBS的集群等。
通常情况下,在太乙上使用Parsl可分为以下四个步骤:
Parsl自动将工作流的各个函数任务在计算节点上并行运行,每一个步骤具体如下:
Parsl 可以像其他 Python 包一样使用 pip 或 conda 安装。例如,在太乙上,我们可以通过Anaconda来管理对应的Python环境:
module load python/anaconda3/2020.11 # 读取太乙上的Anaconda
conda create --name parsl python=3.7 # 使用conda创建Python3.7环境
source activate parsl # 激活conda环境
pip install git+https://github.com/Parsl/parsl.git # Parsl最新版
注2:计算节点也需要安装有Parsl,所以请确保计算节点也可以访问上述Python环境。请参考步骤二配置计算节点的Python环境。
用户通过Parsl的 Config 配置应用需要的计算资源,例如需求的CPU核数量、每个节点的CPU核数量、单个任务需求的CPU核、walltime等,并通过parsl.load(config)读入该配置,Parsl会自动根据配置提交LSF作业(无需自己编写),请求计算节点。当获得计算节点时,Parsl会自动在各个节点上部署worker,每个worker将会负责接收并执行任务,一个worker只能同时执行一个任务,任务完成后返回结果并请求下一个任务,如图2所示。
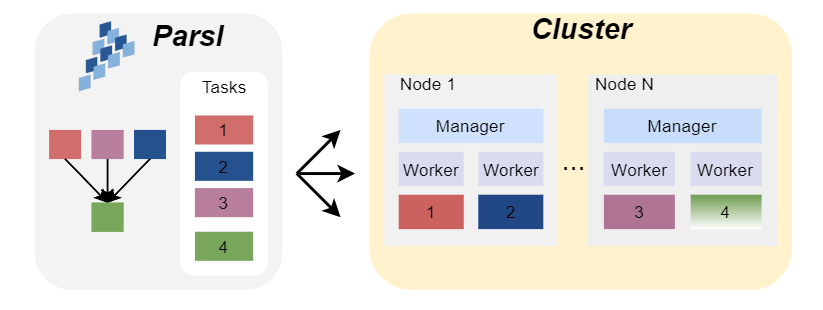
图2:Parsl自动地在各个计算节点部署和执行任务。
下面是一个可在太乙上部署的配置例子:
import parsl
from parsl.config import Config
from parsl.executors import HighThroughputExecutor
from parsl.providers import LSFProvider
from parsl.launchers import MpiRunLauncher
taiyi_config = Config(
executors=[
HighThroughputExecutor(
label="taiyi",
cores_per_worker = 1,
provider=LSFProvider(
queue='debug', # Use debug queue
init_blocks=1,
max_blocks=1,
min_blocks=1,
cores_per_block=80, # Number of cores to request
cores_per_node=40, # Number of cores per node
# Start the Anaconda Environment on Compute Nodes
worker_init="module load python/anaconda3/2020.11 mpi;source activate parsl",
# Other LSF options, for exmaple, GPU
scheduler_options='',
walltime="00:20:00",
request_by_nodes=False,
bsub_redirection=True,
# Use MPI to launch workers on each node
# cpus-per-proc determines how many cpu cores on each node will be used
# in general, cpus-per-proc is equal to cores_per_node above
launcher=MpiRunLauncher(overrides="--map-by node --cpus-per-proc 40"), #default to 40, since there are 40 cores on each node for Taiyi
cmd_timeout=180,
),
)
],
)
parsl.load(taiyi_config)
worker_init="module load python/anaconda3/2020.11 mpi;source activate parsl"用户可以通过Parsl提供的装饰器 python_app 和 bash_app 标注函数以创建Parsl apps,即表示这个函数是需要在计算节点上并行运行。其中python_app装饰python函数,bash_app可以通过命令行执行其他软件或者工具,并获取stdout。当用户使用装饰器标注并调用函数,Parsl将会自动地在各个计算节点上运行这些函数。例如,下面是一个基于Monte Carlo方法的Pi估计应用。本例子中只使用了python_app,如需执行命令行应用以及其他语言编写的应用,请参考Parsl官方文档关于bash_app的介绍。
from parsl.app.app import python_app, bash_app
@python_app
def pi(num_points):
from random import random
inside = 0
for i in range(num_points):
x, y = random(), random()
if x**2 + y**2 < 1:
inside += 1
return (inside * 4 / num_points)
@python_app
def mean(inputs=[]):
return sum(inputs) / len(inputs)
注意:由于python_app可能执行在不同的计算节点上,因此需要在python_app内部import依赖,并保证在计算节点上已安装有该依赖,即在计算节点配置好Python环境,详见步骤二。例如在该例子中,在pi函数内部import random。
在装饰了需要并行的函数后,用户可以调用这些函数,调用被装饰的函数不会直接运行得到结果,而是立即返回一个Python的future object,表示的是尚在运行或者未完成的延迟计算。想要得到最后的结果,需要调用 result() 方法才会得到最终结果。
我们可以通过 future 的传递来构建可表示为有向无环图(Directed Acyclic Graph,DAG)的工作流,Parsl会自动地根据所构建的DAG工作流,将函数发送到有空闲资源的计算节点上并行运行。例如,下面这个例子中我们把 pi 函数返回的futures传递到mean函数中,也就是mean函数的运行将需要等待pi函数的完成。
# Execute 100 pi functions in parallel on the compute nodes
# Return a list of futures that can be passed into mean function
pi_futures = [pi(10**6) for i in range(100)]
mean_pi = mean(inputs=pi_futures)
# Fetch results by calling result()
print(mean_pi.result())
Parsl会根据futures的传递自动构建如下DAG(示意图,实际为100个pi函数调用):

总结:在安装好Parsl后,将上述所有代码(如下框)放在hello_parsl.py文件中,在太乙的登录节点上,通过 python hello_parsl.py 运行该程序。Parsl将在debug队列请求2个节点共80个CPU核,然后在这2个节点并行运行100个pi函数和最后的mean函数,并获取最后结果。
import parsl
from parsl.config import Config
from parsl.executors import HighThroughputExecutor
from parsl.providers import LSFProvider
from parsl.launchers import MpiRunLauncher
taiyi_config = Config(
executors=[
HighThroughputExecutor(
label="taiyi",
cores_per_worker = 1,
provider=LSFProvider(
queue='debug', # Use debug queue
init_blocks=1,
max_blocks=1,
min_blocks=1,
cores_per_block=80, # Number of cores to request
cores_per_node=40, # Number of cores per node
# Start the Anaconda Environment on Worker Nodes
worker_init="module load python/anaconda3/2020.11 mpi;source activate parsl",
# Other LSF options, for exmaple, GPU
scheduler_options='',
walltime="00:20:00",
request_by_nodes=False,
bsub_redirection=True,
# Use MPI to launch workers on each node
# cpus-per-proc determines how many cpu cores on each node will be used
# in general, cpus-per-proc is equal to cores_per_node above
launcher=MpiRunLauncher(overrides="--map-by node --cpus-per-proc 40"), #default to 40, since there are 40 cores on each node for Taiyi
cmd_timeout=180,
),
)
],
)
parsl.load(taiyi_config)
from parsl.app.app import python_app, bash_app
@python_app
def pi(num_points):
from random import random
inside = 0
for i in range(num_points):
x, y = random(), random()
if x**2 + y**2 < 1:
inside += 1
return (inside * 4 / num_points)
@python_app
def mean(inputs=[]):
return sum(inputs) / len(inputs)
# Execute 100 pi functions in parallel on the compute nodes
# Return a list of futures that can be passed into mean function
pi_futures = [pi(10**6) for i in range(100)]
mean_pi = mean(inputs=pi_futures)
# Fetch results by calling result()
print(mean_pi.result())
Parsl具有以下优势:
比方说,上面同一个Pi估算的应用,我们既可以在太乙集群上运行,也可以在本地机器运行。如果我们想在本地机器运行,只需在步骤二:计算资源配置的时候,将Config内的LSFProvider更换为本地机器的LocalProvider即可,例如:
import parsl
from parsl.config import Config
from parsl.executors import HighThroughputExecutor
from parsl.providers import LocalProvider
local_config = Config(
executors=[
HighThroughputExecutor(
label="local",
max_workers=10,
provider=LocalProvider(
init_blocks=1,
max_blocks=1,
min_blocks=1,
nodes_per_block=1,
cmd_timeout=60,
),
)
],
)
parsl.load(local_config)